Abstract
|
|
|
|
|
|
|
|
|
|
|
|
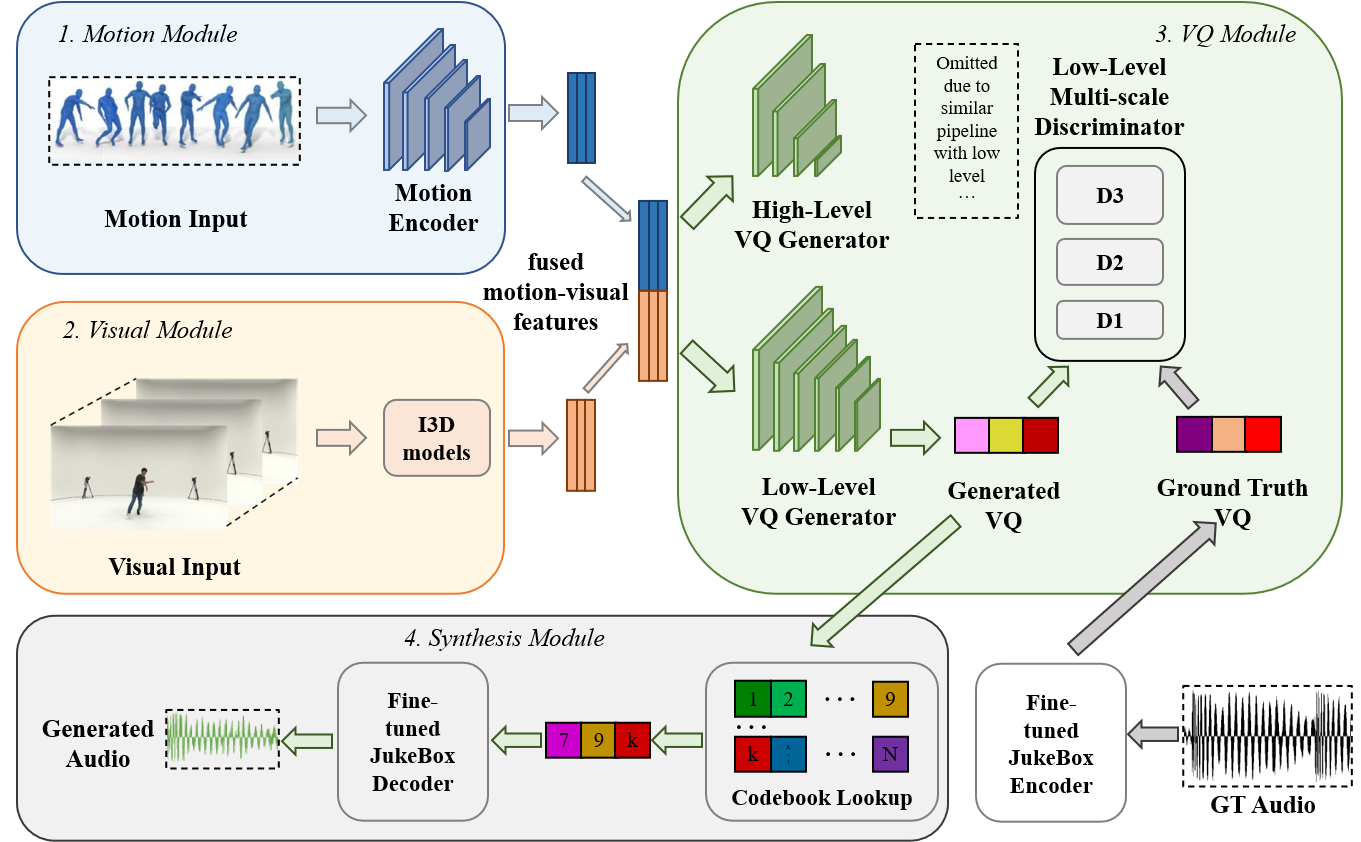
| We present Dance2Music-GAN (D2M-GAN), a novel adversarial multi-modal framework that generates complex musical samples conditioned on dance videos. Our proposed framework takes dance video frames and human body motions as input, and learns to generate music samples that well accompany the corresponding input. |
|
|
|
Current cross-modality music generation works via symbolic representations generate mono-instrumental sounds for dance videos, which do not suit the real-world application scenarios.
(Left: GT video with pop dance and music. Right: sample music generated via MIDI-based methods.) |
| Samples generated from our high-level D2M-GAN. Note that the symbolic musical representation based methods in nature do not contain audio noises due to the pre-defined synthesizers, in contrast to our learning-based synthesizer. |
| Samples generated from our low-level D2M-GAN. |